Sử dụng Scrapy login form để crawl dữ liệu

Hôm nay, khi mình đang chạy crawl như bao lần khác thì tự nhiên nhìn thấy list data bão lỗi. Hì hục check lại code các kiểu thì cuối cùng lại do trang web đang crawl cần phải login mới có thể thấy nội dung trang. Lên mạng tìm kiếm và thấy Scrapy FormRequest.
Scrapy FormRequest được xây dựng với chức năng xử lý các HTML Form. Nó sử dụng các lxml.html forms để điền vào các trường input trong Response trả về.
Ở đây mình sẽ dùng các post resquest để submitting form và authenticationg vào trong site đang crawl từ spiders của mình một cách thông thường như mọi người đăng nhập vậy.(Để hiểu thêm về scrapy, mọi người có thể tham khảo về scrapy ở đây).
Ok, đến luôn đến với ví dụ nhé. Vẫn là trang quotes.toscrape.com
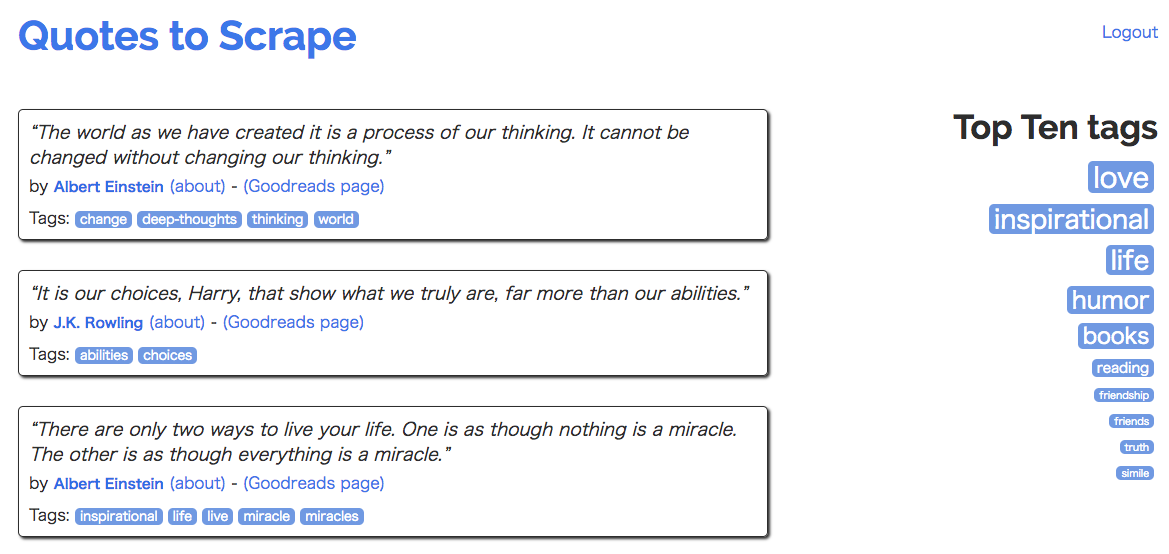
Trước khi login, mình không thể lấy được link (Goodreads page)
Chưa logined

Đã login
Bây giờ, đến trang login và phân tích form. Trong inspect của trình duyệt form gửi lên có 3 input là csrf_token, username, password. Thử đăng nhập với tài khoản bất kì ta thu được form data như sau:
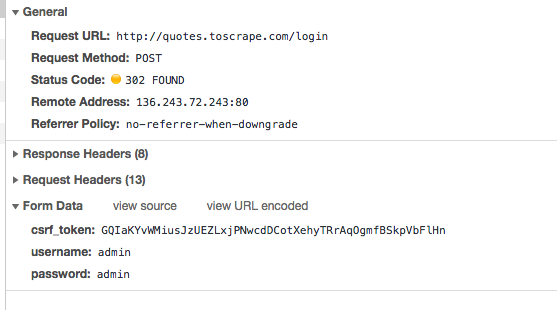
Vậy là trước khi gửi request login, mình phải lấy được csrf_token trong ô input type="hidden".
Tiếp theo, mình tạo 1 con spider trong project scrapy và có nội dung như bên dưới:
import scrapy
class LoginSpider(scrapy.Spider):
name = "login"
login_url = 'http://quotes.toscrape.com/login'
def start_requests(self):
yield scrapy.Request(self.login_url, callback=self.parse)
def parse(self, response):
# extract the csrf token value
# create form value
# Submit Post request login
def parse_quotes(self, response):
""" Parse the main page after spider logined """
for quote in response.css('div.quote'):
yield {
'author_name': quote.css('small.author::text').extract_first(),
'author_url': quote.css('small.author ~ a[href*="goodreads.com"]::attr(href)').extract_first(),
}
Khi chạy start_requests nó sẽ lấy csrf_token trước rồi mới thực hiện submit form.
Hàm parse_quotes: để lấy data các bài quotes(đã giới thiệu chi tiết lấy việc parse data ở bài trước)
Giờ đây mình sẽ thực hiện chính trên hàm parse. Mình thêm:
# extract the csrf token value
token = response.css('input[name="csrf_token"]::attr(value)').extract_first()
# create form value
data = {
'csrf_token': token,
'username': 'admin',
'password': 'admin',
}
# Submit Post request login
yield scrapy.FormRequest(url=self.login_url, formdata=data, callback=self.parse_quotes)
vào hàm parse để sau khi login xong, nó sẽ crawl được link goodreads cho mỗi tác giả của bài viết.
Và bây giờ run spider của mình để xem kết quả thôi.
$ scrapy crawl quoteslogin
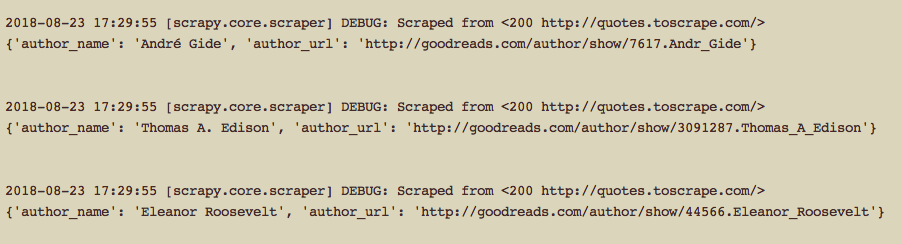
Mình vừa giới thiệu sử dụng FormRequest của Scrapy cho việc submit form login để crawl những dữ liệu cần login mới có thể xem được. Mọi người có thể mở rộng việc crawl của mình bằng cách sau khi login thì crawl các page tiếp theo hoặc tiếp tục submit form... cho phù hợp với dữ liệu muốn lấy về.
Cảm ơn mọi người đã theo dõi.