Scrapy - Thử crawl bóc tách dữ liệu một cách đơn giản

Chào mọi người, mình cumback rồi đây, nhưng nay chán django rồi nên chuyển sang crawl dữ liệu cho có tí mới mẻ.
Mình dùng thằng Scrapy để clawling website và extracting structured data.
Chi tiết về thằng này thì mọi người có thể xem tại đây
Ok, bắt đầu thôi. Trước tiên cứ cài đặt scrapy cái đã. Rất đơn giản, cứ package của python thôi.
$ pip3 install Scrapy
Xong cài đặt thì xác định trang web cần clone. Ở bài này, mình lấy trang http://quotes.toscrape.com trên document cho dễ chơi, dễ trúng thưởng. Mình sẽ lấy các bài viết trên trang đó cùng với tác giả của bài đó nữa.
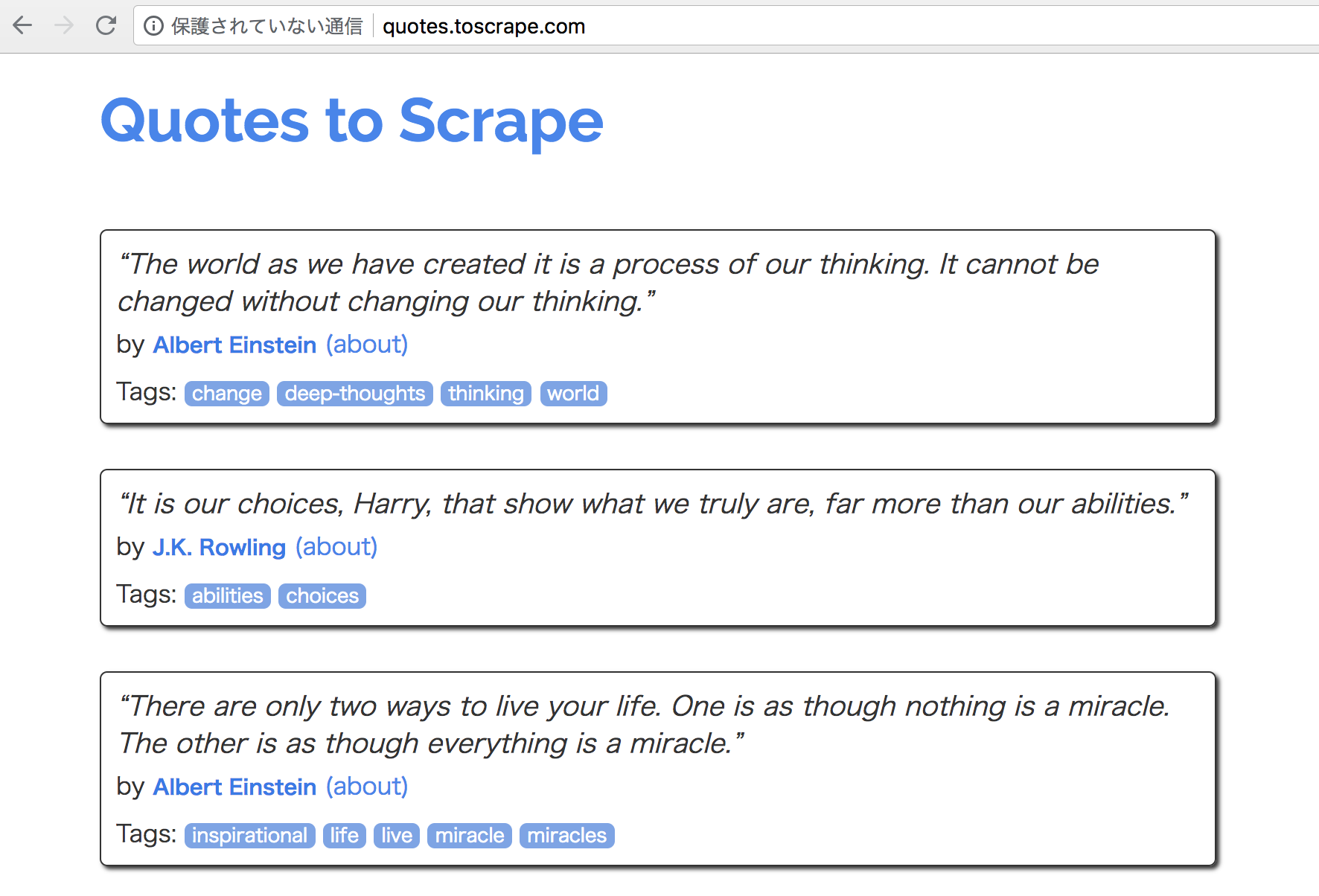
Rồi tiếp theo là bắt tay vào thực hiện thôi!
Tạo Scrapy project
scrapy startproject quotes
thư mục project quotes sẽ được tạo ra với nội dung:
quotes/
scrapy.cfg # deploy configuration file
quotes/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
Tạo Spider
Tạo một file tên là quotes_spider.py trong thư mục spiders đã được tạo ở trên và đây cũng là file thao tác chính trong bài này. Thư mục là nơi mọi người đưa ra các chỉ định cho Scrapy biết muốn thu thập dữ liệu gì. Trong thư mục này, mọi người có thể định nghĩa các Spider khác nhau cho các trang Web khác nhau.
Trước tiên cứ thêm các định nghĩa ban đầu cho spider(quotes_spider.py) đã.
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
start_urls = [
'http://quotes.toscrape.com/page/1/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
Ta thấy, trong mỗi quote được thể hiện giống như sau:
<div class="quote">
<span class="text">“The world as we have created it is a process of our
thinking. It cannot be changed without changing our thinking.”</span>
<span>
by <small class="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
Để crawl dữ liệu, ta dùng CSS trong response khi call đến site.(Ngoài CSS còn có XPath nhưng để thao tác đơn giản hơn với HTML thì mình dùng XPath). Mình tạo hàm parse để crawl ra nội dung của các quotes.
Trong quotes_spider.py mình thêm:
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('small.author::text').extract_first(),
'tags': quote.css('div.tags a.tag::text').extract(),
}
Giải thích thêm là:
- response.css('div.quote') nó sẽ lấy tất cả bài quotes có thẻ HTML là
- quote.css('span.text::text').extract_first() có ::text sẽ lấy text trong thẻ qua extract_first()
- 'tags': quote.css('div.tags a.tag::text').extract() lấy tất cả tags của bài quote, trả ra array
Chạy Spider thôi
$ scrapy crawl quotesnó sẽ gửi một số request cho quotes.toscrape.com và nhận được phản hồi (response) và chúng ta sẽ bóc tách data từ response mà chúng ta vừa nhận được bằng hàm
parse. Và kết quả:

Để lưu ra file json
$ scrapy crawl quotes -o quotes.jsonCrawl in next_page
Để crawl không chỉ trong 1 page mà ở tất cả các page bằng cách lấy liên kết page tiếp và đệ quy
parsevới mỗi liên kết.
Thêm đoạn sau vào cuối parsenext_page = response.css('li.next a::attr(href)').extract_first() if next_page is not None: yield response.follow(next_page, callback=self.parse)và run lại spider là có thể lấy được tất cả các bài quote trong quotes.toscrape.com.
Trên đây, mình vừa giới thiệu nhẹ ví dụ đơn giản về crawl bằng Scrapy. Mọi người có thể tham khảo thêm tại: https://docs.scrapy.org/en/latest/index.html